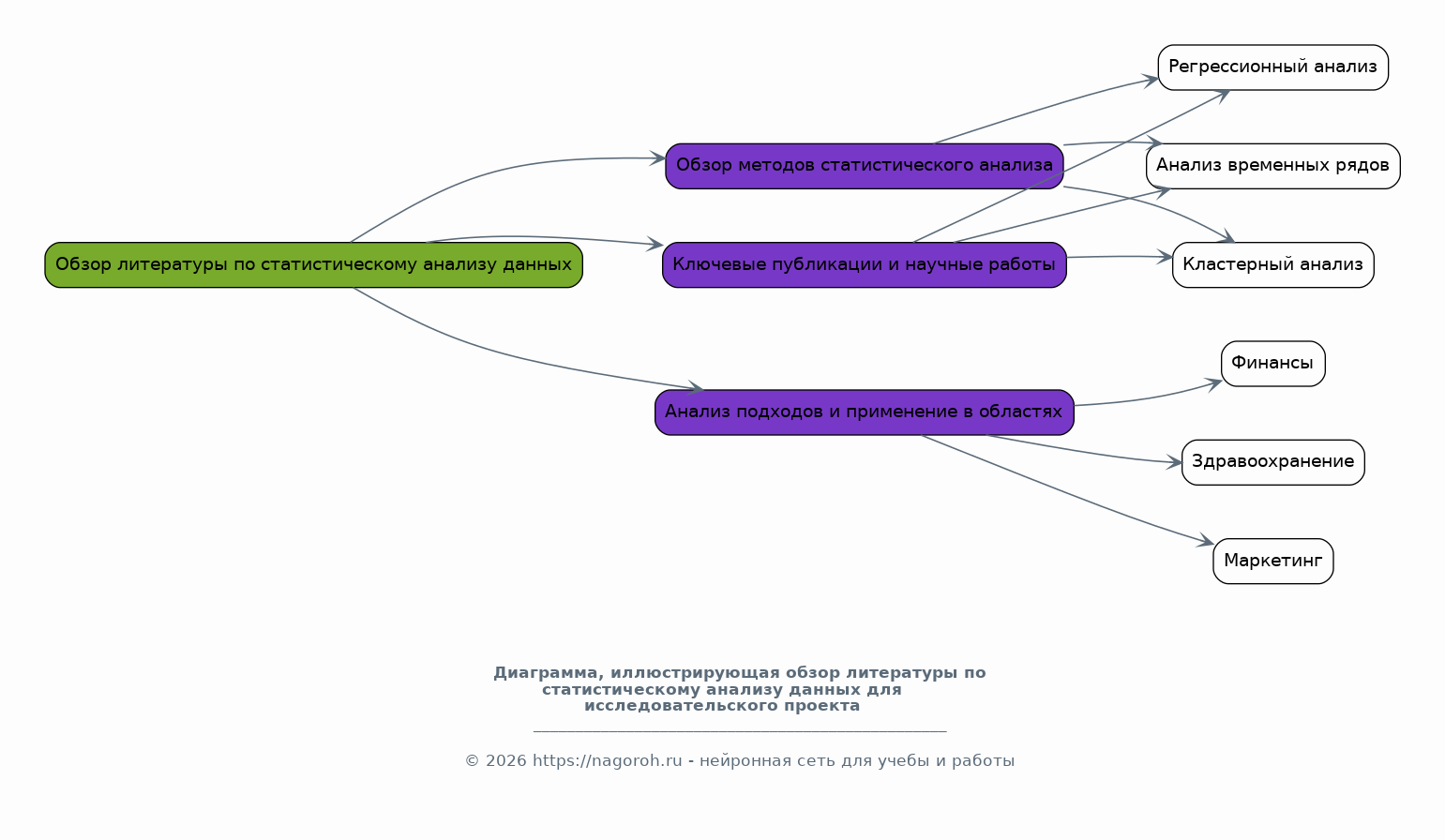
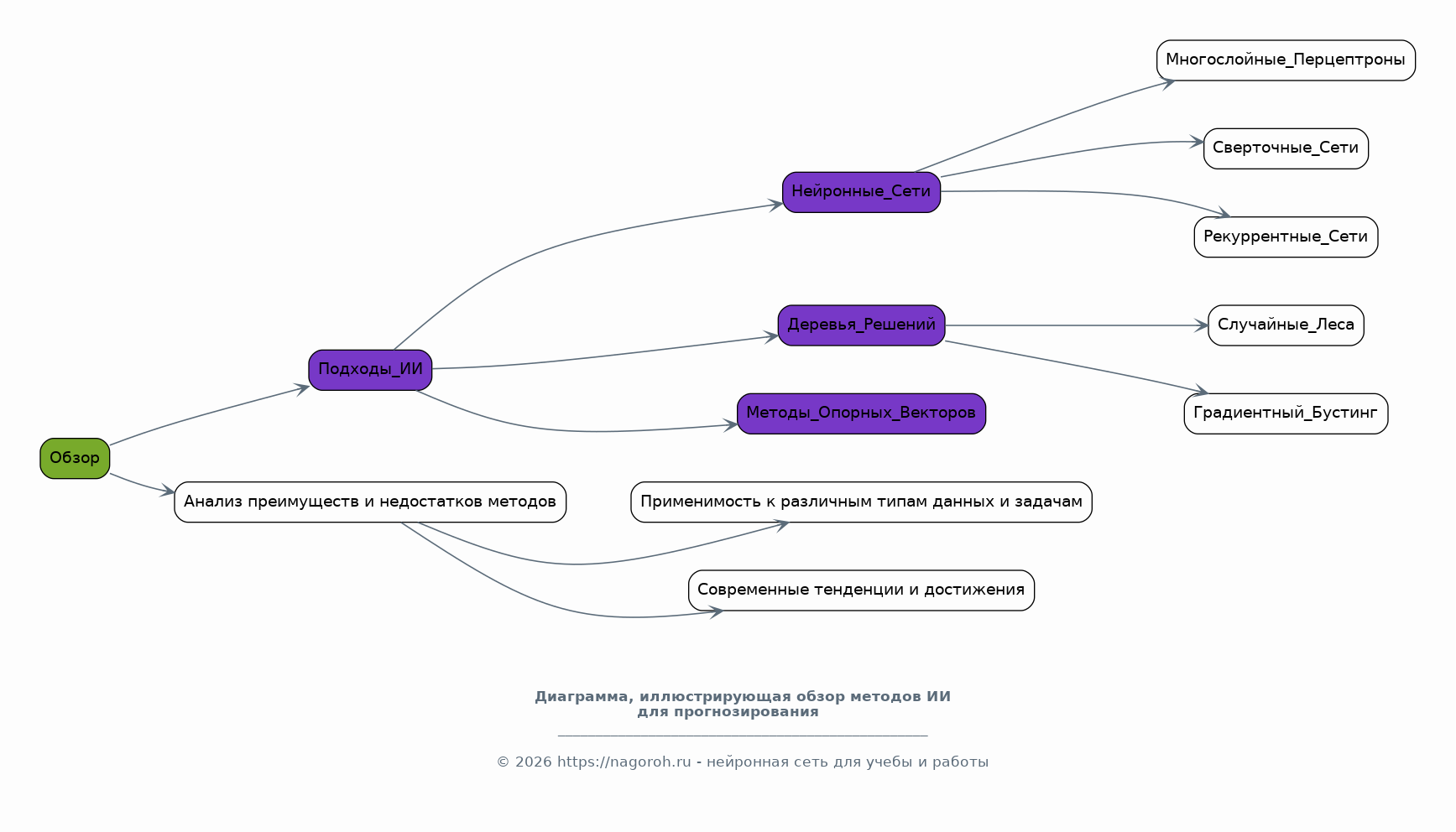
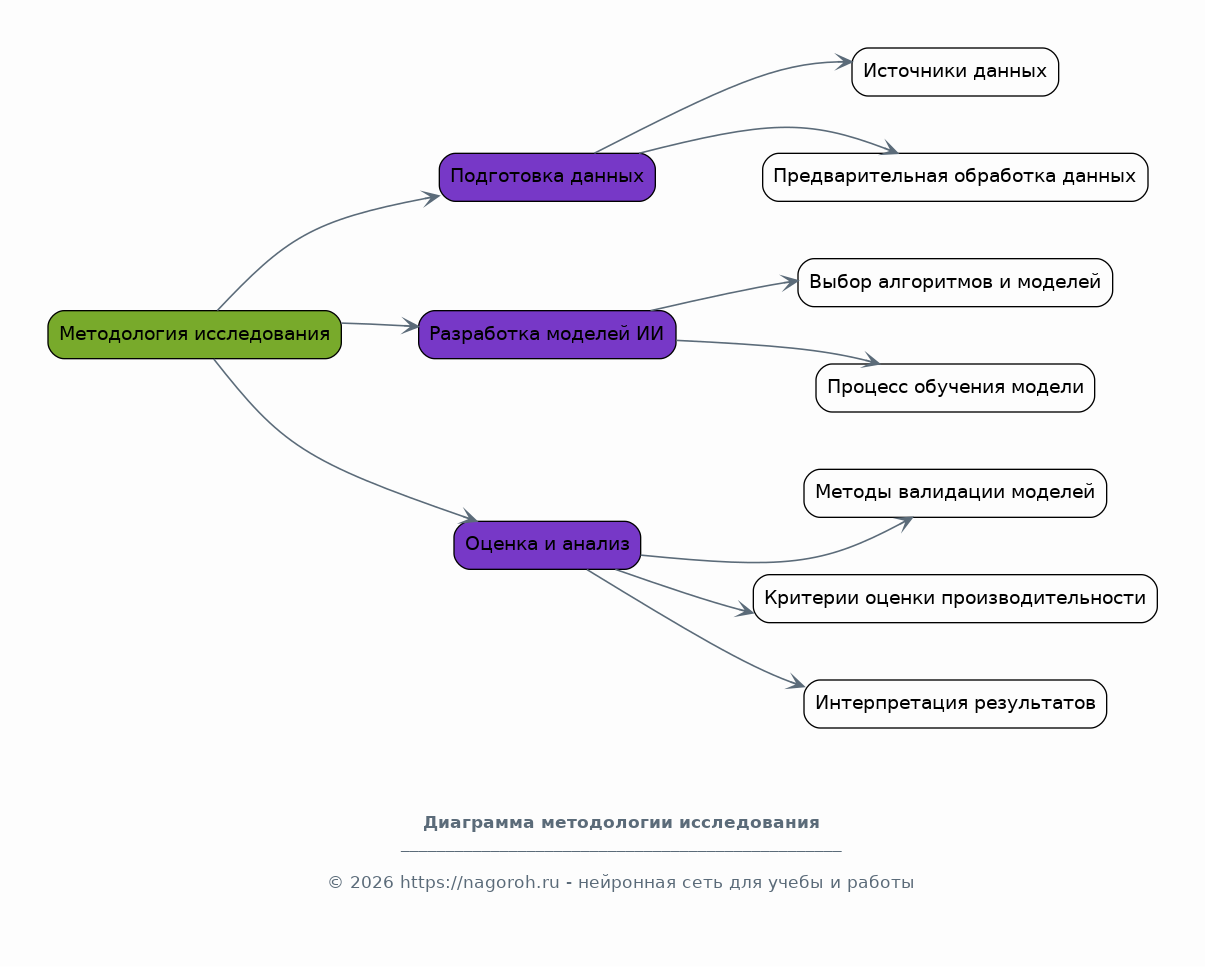
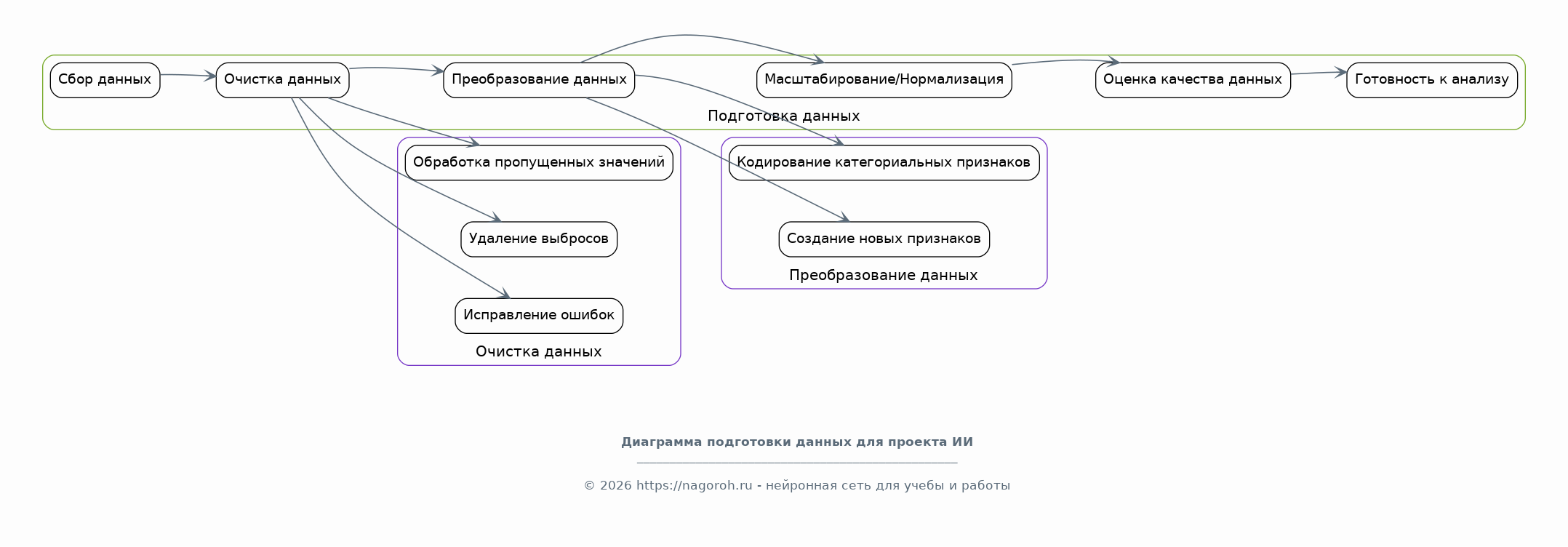
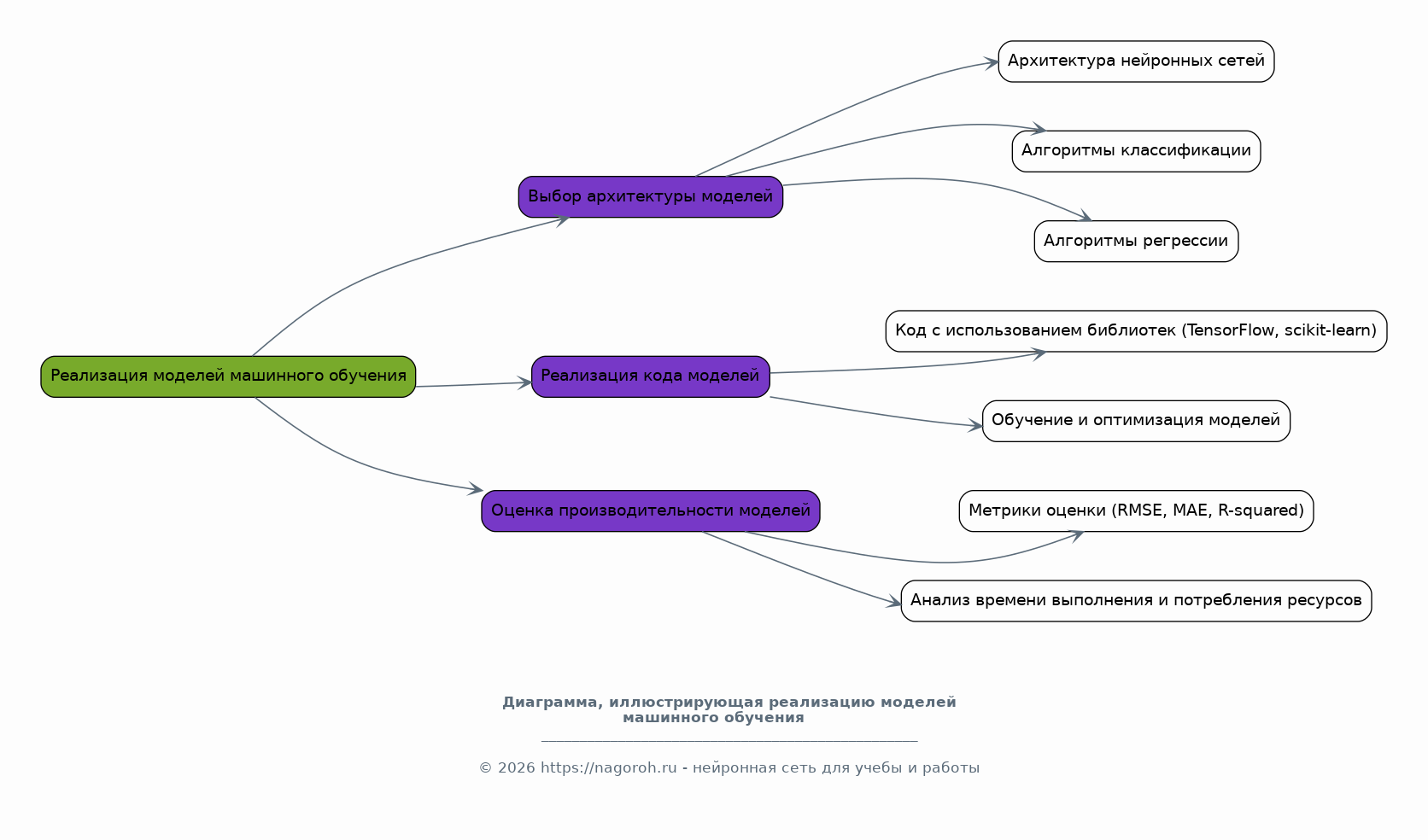
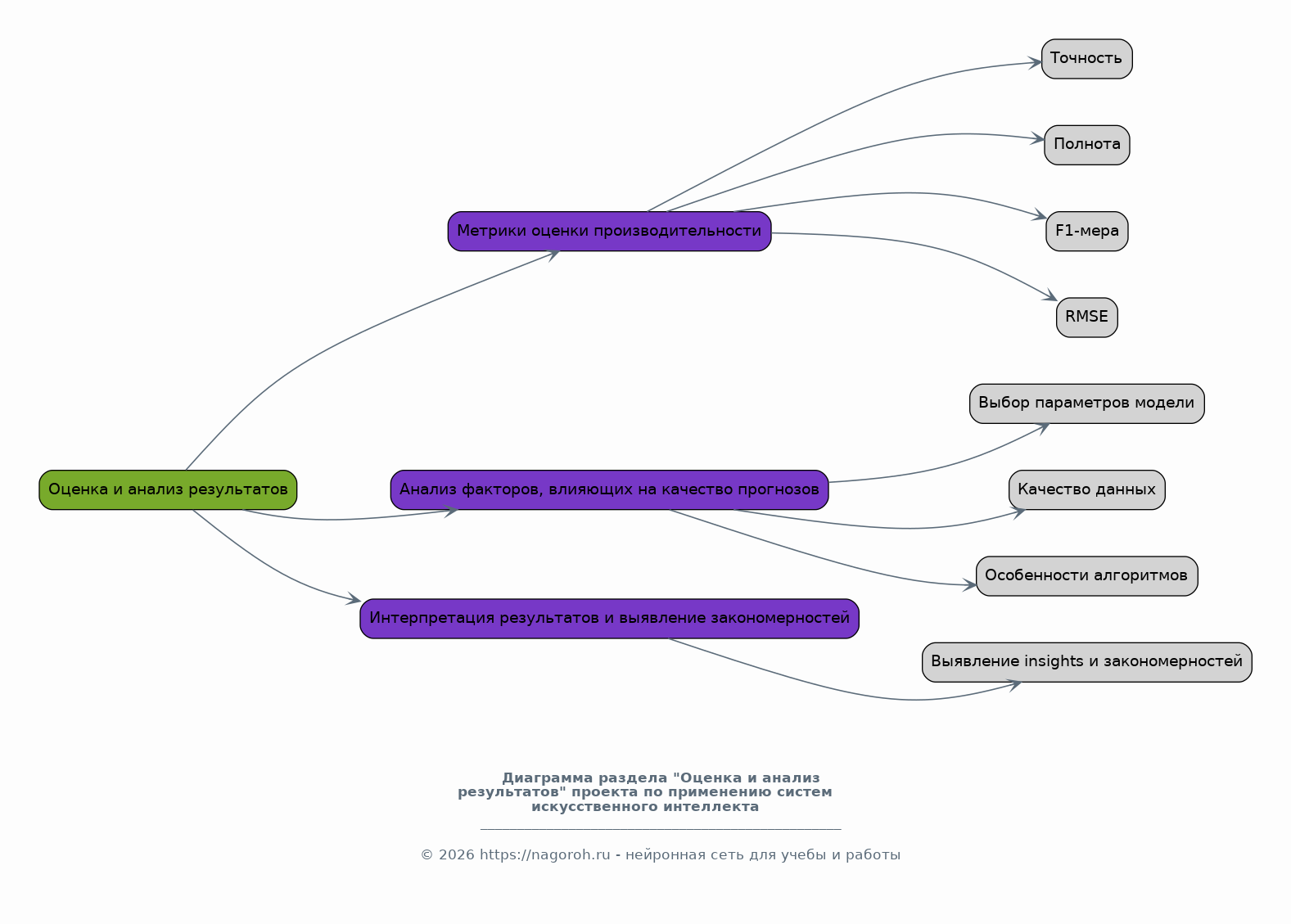
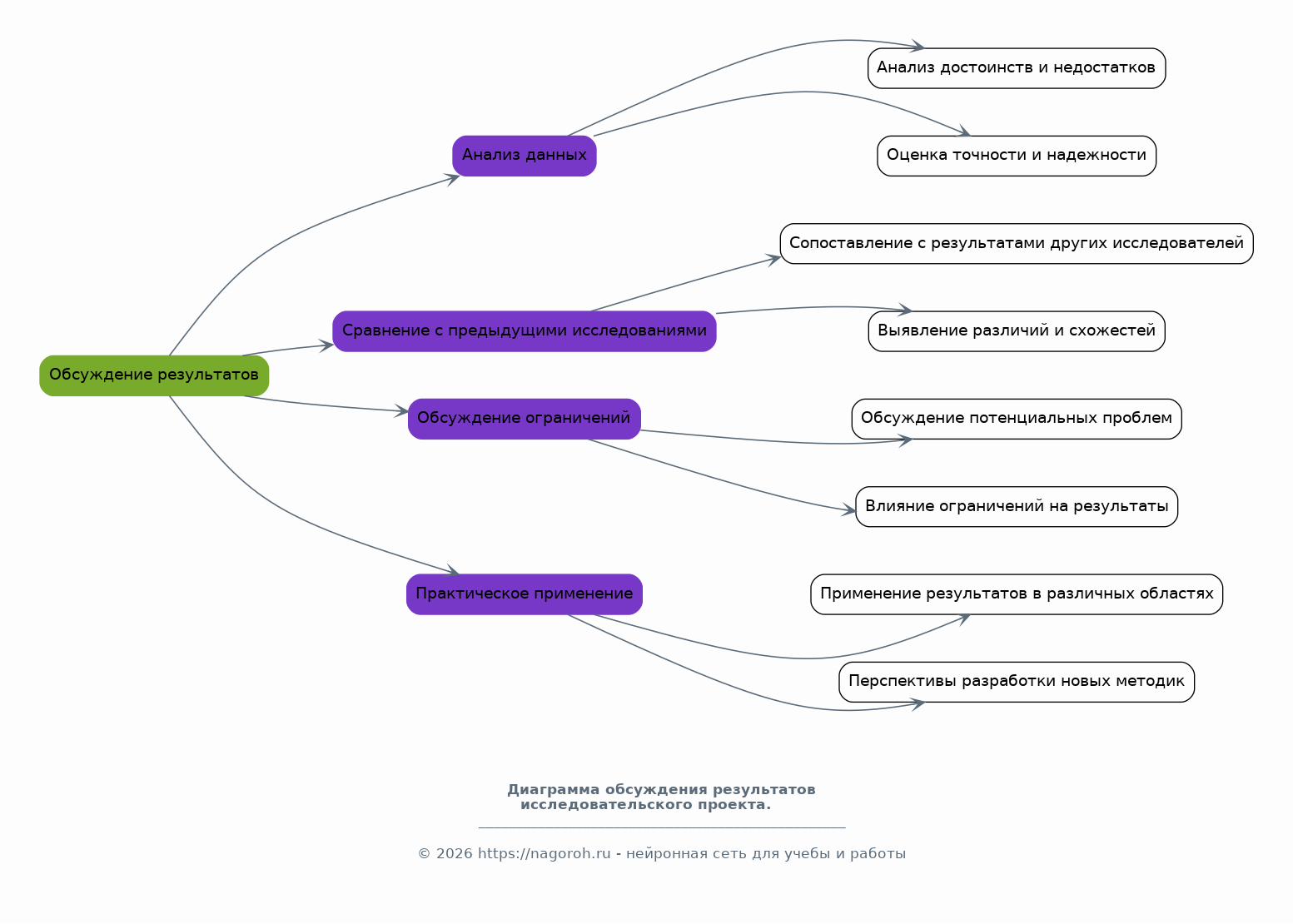
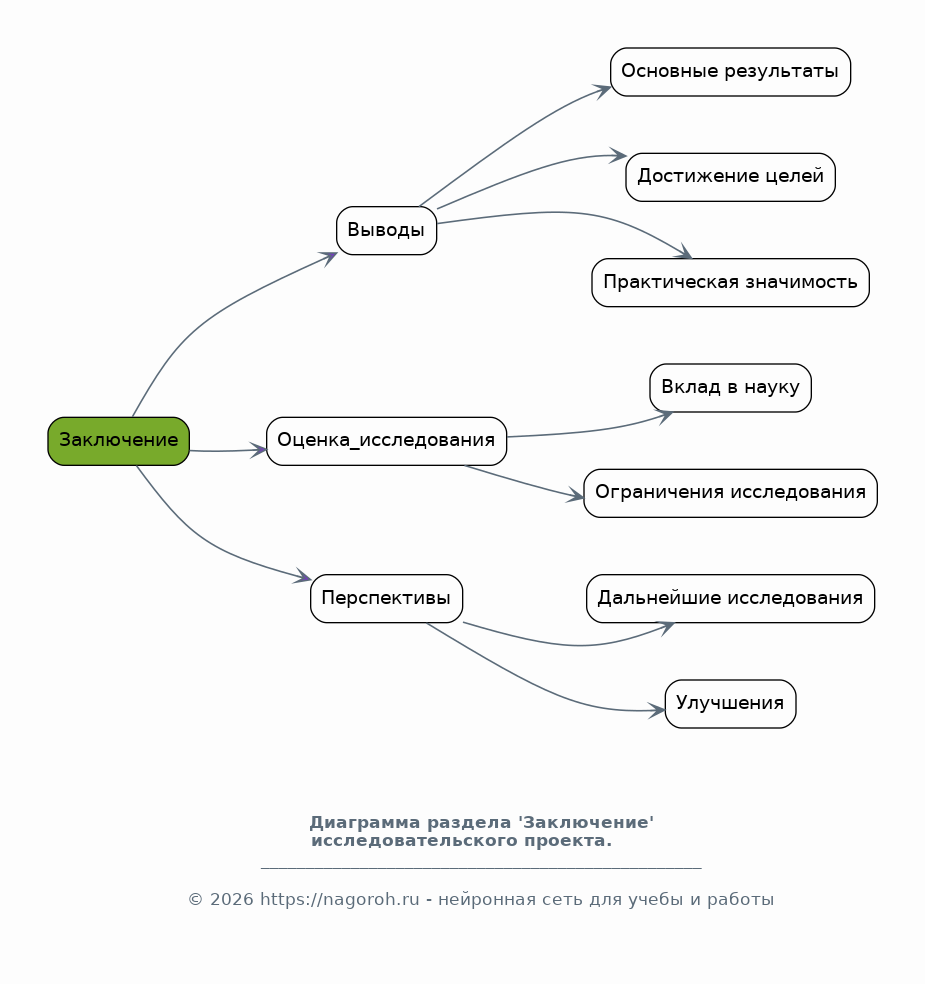
Данный исследовательский проект посвящен изучению и практическому применению современных систем искусственного интеллекта (ИИ) в области статистического анализа данных и прогнозирования. Проект направлен на всесторонний анализ существующих методов и алгоритмов ИИ, пригодных для обработки больших объемов данных, выявления скрытых закономерностей и построения точных прогнозных моделей. В рамках исследования будут рассмотрены различные типы данных, включая временные ряды, табличные данные и данные, полученные из различных источников, таких как базы данных, веб-сервисы и API. Особое внимание будет уделено разработке и тестированию моделей машинного обучения, способных решать задачи классификации, регрессии, кластеризации и прогнозирования. Проект также предусматривает анализ эффективности различных алгоритмов ИИ, таких как нейронные сети, деревья решений, случайные леса и методы опорных векторов, с целью выбора наиболее подходящих для конкретных задач анализа и прогнозирования. В процессе работы над проектом будут использованы современные программные инструменты и библиотеки, такие как Python, TensorFlow, PyTorch, scikit-learn и библиотеки для визуализации данных, что позволит создать эффективные и масштабируемые решения. Результаты исследования могут быть применены в различных областях, включая финансы, здравоохранение, маркетинг, логистику и другие отрасли, где требуется анализ данных и прогнозирование.